在几秒钟内杀死您的同龄人! Kimi开源新的音频基
时间:2025-04-28 10:41 作者:bet356亚洲版本体育
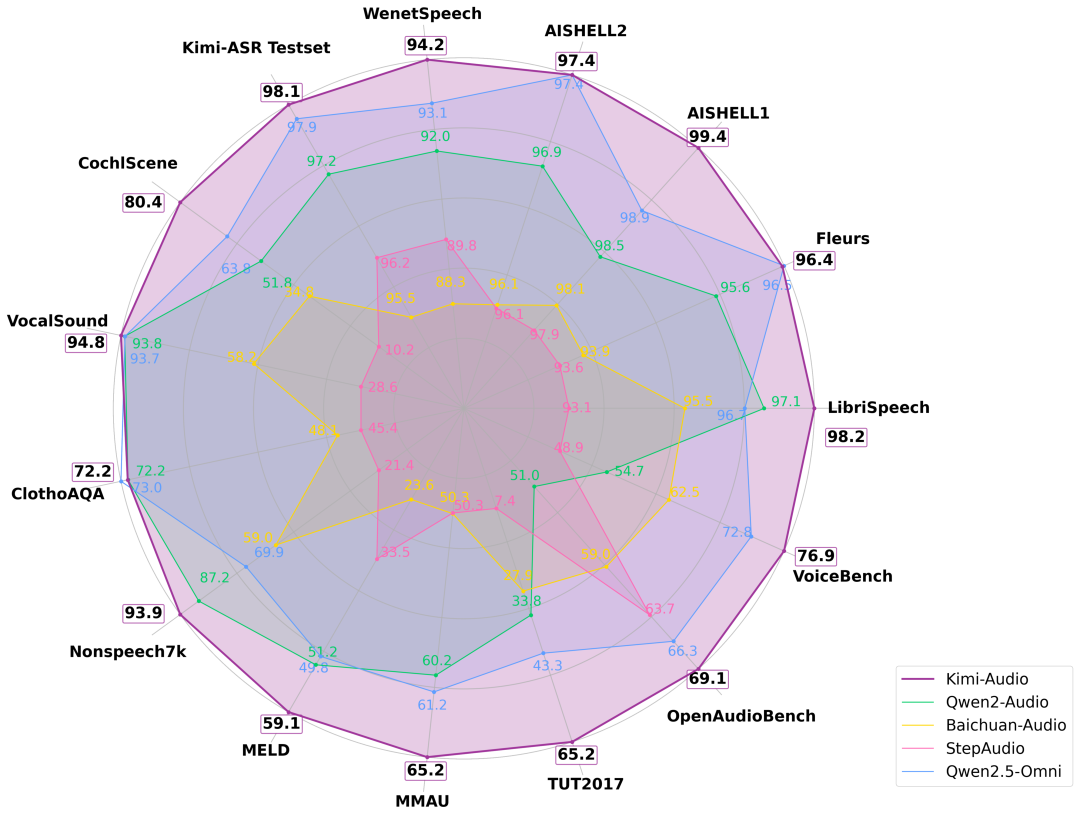
机器核心报告的编辑:Sia,Wen Hexagonal Warrior在这里。如今,Kimi发布了一个新的开源项目 - 新的新通用音频基本模型Kim-Audio,该模型支持各种任务,例如语音识别,音频理解,文本音频,语音对话等以及在多个音频基准中实现最先进的ART(SOTA)性能。结果表明,音频以前是一般性能的排名,几乎没有明确的缺点。例如,Kimi-Audio的WER仅为1.28%,比其他ASR库测试模型要好得多。在Vovalsound测试中,Kimi在整个标记附近达到94.85%。 Kimi-Audio在MMA的作品中获得了两个最高分。 VoiceBench旨在检查对话中对话助手的声音的理解,Kimi-Audio在所有子任务中都评分为最高分数,包括完整的标记。研发人员已经开发了一个评论工具包,可以执行公平,全面的Revi在许多基准活动中,音频LLM的EW。在各种音频基准测试中的五种音频模型(Kim-Audio,Qwen2-Audio,Baichuan-Audio,Stepaudio,Qwen2.5-OMNI)的性能比较。紫色线(Kimi-Audio)通常覆盖最宽的层,表明它通常表现最好。当前,模型代码,模型检查点和审核工具包是GitHub的开放资源。项目链接:https://github.com/moonshotai/kimi-audio's Design Architecture旨在实现SOTA-LEVEL通用音频建模,音频采用了集成的建筑设计,包括三种主要的成分Audio Tokenizer,Audio audio llm和Audio DeKenizer。这种体系结构使Kim-Audio能够从说话识别,了解语音对话以及模型框架中的其他人来正确处理音频语言活动。音频由三种主要成分组成:音频令牌,音频LLM和音频detotenizer。具体而言,音频令牌器负责将输入音频转换为DIST通过向量体积获得的ETE语义令牌,帧速率为12.5Hz。同时,音频单词细分器还需要连续的声学向量来增强理解。这种组合使该模型具有相同的语义压缩表示并保持丰富的声学细节,从而使其更多的音频任务提供了扎实的表示。 Audio LLM是系统的主体,该系统负责开发语义令牌和文本令牌,以提高发电的能力。它的体系结构基于共享变压器层,能够处理多模式输入,然后在两个统一的输出标头上进行分支,该标头侧重于文本和音频生成。音频解次仪使用流程匹配方法将音频模型预测的离散语义令牌转换为一致的音频波,以产生高质量的表达声音。除了新型模型的结构外,开发SOTA的主要任务模型还包括建筑和培训技术。为了实现SOTA级通用音频建模,Kimi-Audio使用了大约1300万小时的音频数据,这些音频数据涵盖了许多情况,例如多语言,音乐,周围的声音等。预训练后,使用微调(SFT)管理模型,数据涵盖了三个主要任务:音频理解,语音和音频到文本聊天对话,进一步改进命令后续措施和音频生成功能。音频预训练的数据处理流的直观显示。简而言之,这是为了清洁,分裂和调整原始音频步骤,并将其放入干净,结构化和标记的培训数据中。在培训方法方面,为了获得强大的音频理解和发电的能力,同时保持模型智能,R&的知识能力和水平D人员已经开始预培训模型NG语言,并设计了三类预训练任务:仅文本和仅音频的预训练,用于确定两种方式的知识;音频到文本映射促进模态转换功能;音频文本交流训练,以进一步弥合方式之间的差距。在进行精细舞台调整期间,他们设计了一套培训公式,以提高培训效率和整体工作技能。考虑到差异 - 下游任务,研究人员没有设置特殊的工作转移操作,而是使用自然语言作为每个任务的指示;为了说明,他们构建了音频和文本版本(即,根据零样本模式的kimi-tts的文本形成的音频),并由其中一个练习随机选择;为了增强遵循说明的能力的稳定性,他们使用大语言模型为ASR任务设置了200个说明,30个指令S用于其他任务,并由一个随机选择每个训练样本。他们构建了将近300,000个小时的数据,以精细精制。如表1和表2所示,根据全面的消融实验,它们在每个数据源中具有良好的音频,使用ADAMW优化器,研究速率是余弦率从1E⁻⁵到1E⁻⁶衰减,使用了10%的研究率。此外,他们在三个阶段训练了音频解码器。首先,使用大约100万小时的预先数据音频,对与模型和Vocoder相对应的流进行训练,以找出具有不同TONO,音调和质量的音频。其次,在相同的数据假装中,使用细微调整方法将块大小的大小更改为0.5秒至3秒。最后,Kim-Audio演讲者提供的高质量单录制数据的微调。审查的结果基于评论的工具包,研究人员在一组中审查了Kimi-Audio的表现音频处理活动,包括自动语音识别(ASR),音频理解,音频到文本聊天和语音对话。他们使用既定的基准测试和内部测试集将音频与其他音频基础模型(Qwen2-Audio,Baichuan-Audio,Step-Audio,Glm4-Voice和Qwen2.5 -Ini)进行了比较。研究人员回顾自动识别音频识别(ASR)的功能,涵盖了不同的数据集多种语言和声学条件。如表4所示,Kim-Audio在这些数据集中的先前模型中继续表现出出色的性能。他们在这些数据集中报告单词错误率(WERS),其中较低的值表明性能更好。值得注意的是,Kimi-Audio在广泛使用的Librispeech基准中取得了最佳结果,该基准在测试清洁中达到了1.28的错误率,在测试过程中达到了2.42的错误率,大大超过了Qwen2-Audio-Base和Qwen2.5-omni的模型。 Kimi-Audio实现了最先进的资源Aishell-1(0.60)和Aishell-2 iOS(2.56)的LTS上的LTS在普通话的基准上。此外,它不仅仅是具有挑战性的Wenetspeech数据集,还达到了测试和测试网络中最低的错误率。最后,对内部测试的KIMI-ASR中研究人员的综述证实了该模型的稳定性。这些结果表明,音频在各个领域和语言中具有很强的ASR能力。除了说话认可外,研究人员还了解音频,还审查了Kimi-Audio了解各种音频信号(包括音乐,声音事件和语音)的能力。表5总结了不同音频理解基准测试的性能,并且通常更高的分数表明性能更好。在MMA基准上的声音上的音频Audio在类别(73.27)和语音类别(60.66)中显示出了很好的理解。同样,它在融合语音情感理解中也超越了其他模型,其标记为59.13。 Kim-Audio还领导任务Inv在声学场景分类(TUT2017和Cochlscene)中,将非声音(Vovalsound和nonspeech7k)的声音分类(Vovalsound和nonspeech7k)发放。这些结果具有Kimi-Audio的高级能力,可以解释不超出简单语音识别的复杂声学信息。音频到文本聊天研究人员使用OpenAudioBench和VoiceBench基准测试Kimi-Audio根据音频输入进行文本演讲的能力。这些基准测试了诸如遵守指导,问题和答案以及推理之类的方面。性能指标因基准而异,得分较高,表明沟通能力更好。结果显示在表6中。在Openaudiobench中,Kimi-Audio在许多子任务中都取得了最新的表现,包括Alpacaeval,Llama问题和Triviaqa,并在推理质量质量质量检查和网络问题上实现了高度竞争的追求。 VoiceBench分析进一步证实了音频的优势。它继续超过所有山帕瓦尔的比较模型S(4.46),Commoneval(3.97),SD-QA(63.12),MMSU(62.17),OpenBookQA(83.52),Advbench(100.00)和Ifeval(61.10)。 Kimi-Audio在这些全面的基准测试中的总体表现显示了基于音频的对话和复杂推理活动的更好技能。最后,他们根据多维主观评估回顾了金·奥德奥(Kim-Audio)的端到端语音功能。如表7所示,基于人类评分(1-5级,更高的标记,更好),Kim-Audio和GPT-4O模型和GLM-4-voice进行了比较。除GPT-4O外,Kimi-Audio在情绪控制,同理心和Bilis的控制方面得分最高。尽管GLM-4-VOICE在口音控制方面的表现略好,但金·奥德奥的总体平均得分高达3.90,超过了Step-Audio-Chat(3.33)(3.33),GPT-4O-MINI(3.45)(3.45)和GLM-4-4-VOICE(3.65),并且与GPT-4O(4.06)(4.06)。通常,评论的结果表明,音频正在领导表达和契约的发展声音。





